
Data Viz Cheat Sheet
plt.figure(figsize = [10, 5]) # larger figure size for subplots
# example of somewhat too-large bin size
plt.subplot(1, 2, 1) # 1 row, 2 cols, subplot 1
bin_edges = np.arange(0, df['num_var'].max()+4, 4)
plt.hist(data = df, x = 'num_var', bins = bin_edges)
# example of somewhat too-small bin size
plt.subplot(1, 2, 2) # 1 row, 2 cols, subplot 2
bin_edges = np.arange(0, df['num_var'].max()+1/4, 1/4)
plt.hist(data = df, x = 'num_var', bins = bin_edges)
plt.xlim(0, 35)
plt.xticks(np.arange(2, 12+1, 1))Base Color and Order
# Use only 1 color because other colors give no extra meaning
base_color = sb.color_palette()[0]
sb.countplot(data = df, x = 'cat_var', color = base_color)
# Sort the data by highest / lowest value
cat_order = df['cat_var'].value_counts().index
sb.countplot(data = df, x = 'cat_var', color = base_color, order = cat_order)
# Order with ordinal categories
# this method requires pandas v0.21 or later
level_order = ['Alpha', 'Beta', 'Gamma', 'Delta']
ordered_cat = pd.api.types.CategoricalDtype(ordered = True, categories = level_order)
df['cat_var'] = df['cat_var'].astype(ordered_cat)Get proportions or relative frequencies
Use text annotations to label the frequencies on bars
Bins
Scales and Transformations (Log)
Jitter, Transparency and Overplotting
Heatmap
Legend
2 Categorical Variables
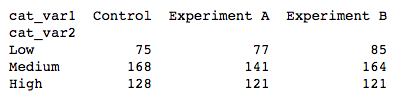

Faceting
Line Plots
Adapted Bar Plot

Encoding via shape

Encoding via size
Encoding via color


Faceting for multivariate data


Plot Matrices
Correlation Matrices
Last updated
Was this helpful?